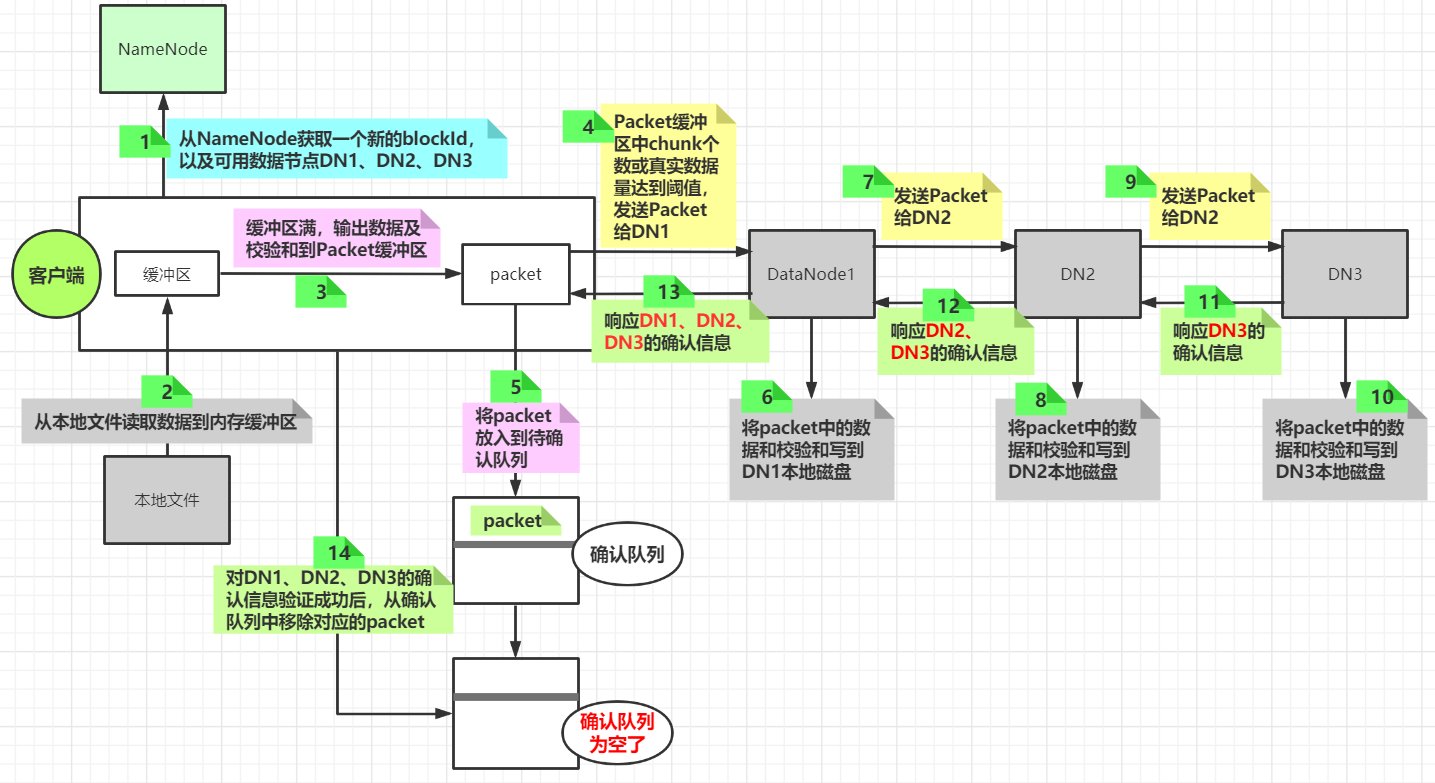
先看下数据写入的流程图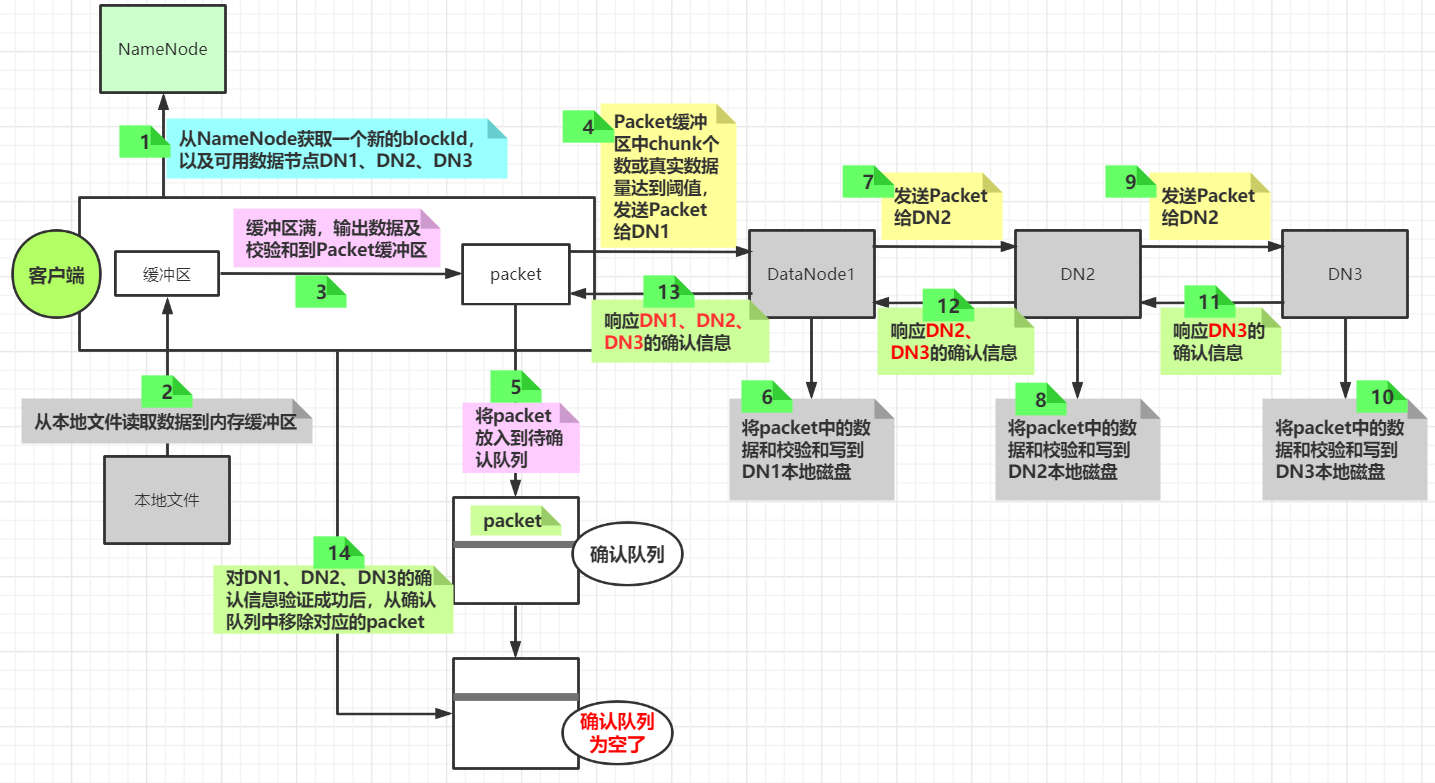

一个packet写入流程
以文字形式梳理上述步骤
目标
- 将一个本地文件a.txt上传到hdfs文件系统中,hdfs中默认blockSize=128M
- 复制因子默认为3
详细步骤
- 客户端根据配置信息与NameNode建立连接,并告诉NameNode,将a.txt文件上传到hdfs的/tmp/a.txt路径
- NameNode生成一个值为1的blockId(用来创建对应blockId的block文件),并根据复制因子3返回对应个数的可用来存放当前block的DataNode节点到客户端,比如(DN1、DN2、DN3)
- 客户端与DN1建立连接,然后将blockId、DN2、DN3等相关数据先发送给DN1
- DN1接收到这个信息之后与DN2建立连接,然后将blockID、DN3等相关数据发送给DN2
- DN2接收到这个数据之后与DN3建立连接,然后将blockID发送给DN3
- 客户端读取本地文件内容并放入内存缓冲区中,当缓冲区满,开始将缓冲区中的数据取出,并计算校验和(每512字节的实际数据会计算出一个4字节的校验和,这512字节的数据和校验和称为一个chunk),然后这个chunk写入到一个dataPacket中,当dataPacket中chunk的数量或实际数据大小达到一定阈值后将这个dataPacket发送给DN1,并将这个dataPacket放入到一个ackQueue队列中(当客户端接收到DN1的确认写入的信息之后才将这个dataPacket从队列中移除)
- DN1接收到客户端发送的数据之后,将dataPacket中的数据和校验和写入本地文件中,然后将dataPacket发送给DN2
- DN2接收到DN1发送的数据之后,将dataPacket中的数据和校验和写入本地文件中,然后dataPacket发送给DN3
- DN3接收到DN2发送的数据之后,将dataPacket中的数据和校验和写入本地文件中,然后发送确认信息给DN2
- DN2接收到DN3的确认消息之后将DN2自己的确认信息和DN3的确认信息发送给DN1
- DN1接收到DN2发来的确认信息后(包含DN2和DN3的确认信息),将DN1自己的确认信息和DN2、DN3的确认信息一起响应给客户端
- 客户端接收到信息之后对DN1、DN2、DN3的确认信息进行验证,验证成功,则将ackQueue中的dataPacket移除
- 客户端继续执行同样的操作,直到发送出的真实数据量达到blockSize大小,此时一个block的写入完毕
注意
- 当客户端发送数据的字节数量达到一个blockSize之后,会向NameNode重新请求一个新的blockId及相关的DataNode信息哦
下面以流程图的方式加深数据写入DataNode过程的理解
图示(以一个packet写入为例)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,请发送邮件至624739273@qq.com举报,一经查实,本站将立刻删除。